最近几年,如果你一直在关注 AI 领域的进展,可能会有一种眼花缭乱的感觉。视频生成、机器人、自动驾驶、AR/VR、游戏开发甚至是 Agent 仿真,各种概念层出不穷。但如果你把这些技术的外壳剥开,会发现它们底层其实都在试图解决同一个大问题——构建世界模型(World Models)。简单来讲,只要一个系统符合这个直觉:当前状态 + 当前动作 -> 下一状态,它就可以被认为是一个世界模型。用公式表达就是极简的:
一旦我们拥有了这个准确的动力学模型 ,后续所有的决策问题,其实都可以转化为一个标准的最优控制问题。这也是为什么前面提到的那么多前沿方向,最终都可以被收拢到这个通用框架里。
从“心智模型”到 AGI
其实“世界模型”这个概念一点也不新鲜,我们在很小的时候,脑子里就已经长出了这东西。比如,小孩子看到水龙头,就知道拧开它“水会流出来”。
在心理学上,这最早被称为心智模型(Mental Model)。Kenneth Craik 在《解释的本质》一书中最早提出了这个概念:人类在对现实做出反应之前,脑子里会先偷偷构建一个小规模的、关于世界如何运作的模型,用来在脑内模拟可能发生的过程,然后才基于这个“脑内推演”去做出真实的物理行动。
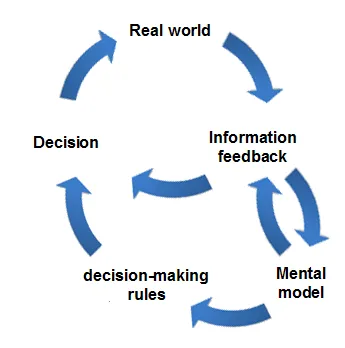
到了 2018 年,Google Brain 正式提出了《World Models》这篇开创性的论文(其实这背后的祖师爷是 LSTM 之父 Schmidhuber,他很早就开始系统性地用神经网络来建模环境动力学了)。在这套体系里,世界模型 = 视觉 + 记忆 + 控制。
而我们今天反复提及世界模型,是因为它指向了那个终极目标:AGI(通用人工智能)。
为什么光靠大语言模型不够?
过去两三年,LLM(大语言模型)可谓出尽了风头。但我们需要建立一个基本认知:LLM 实际学习的只是人类语言的统计规律,它对真实的物理世界几乎没有建模能力。
人类语言的信息密度极大,充满了高度提纯的逻辑;但现实世界运转的法则(比如重力、摩擦、三维空间)往往是低信息密度的,且规律性截然不同。
我们可以直观对比一下这两者:
| 维度 | 大语言模型 (LLM) | 世界模型 (World Model) |
|---|---|---|
| 核心目标 | 建模语言统计规律,生成连贯文本 | 理解环境动态规律,预测行动结果,用于决策 |
| 输入模态 | 文本(Token 序列),部分多模态 | 观测(图像、状态向量)+ 动作 |
| 输出模态 | 下一个 Token / 完整响应 | 未来观测、奖励或隐状态变化 |
| 训练数据 | 海量无标注语料(网页、书籍) | 智能体与环境交互的轨迹数据 |
| 推理模式 | 自回归生成后续文本 | 给定初始状态和动作,自回归“做梦”推演未来 |
| 世界知识 | 从文本中学习关于世界的描述性知识 | 从交互中学习世界的动态规律(因果结构) |
未来的方向已经很明确了:LLM 和世界模型是互补的,两者结合才是通向 AGI 的完整拼图。 LLM 负责 Pre-Training(打底常识),而世界模型负责 Post-Training(在物理世界中验证和执行)。
为什么大家现在都在卷“具身智能”?
风向之所以从纯文本大模型转向具身智能,核心无外乎三点:
- Scaling Law 的疲态:GPT 的纯文本路线已经逼近天花板,单靠堆数据、堆算力,改模型架构,已经很难再等比例地获得惊艳的智能涌现了。
- 传感器、激光雷达、视频流等多模态数据的海量出现。
- 算力的跃迁使得处理复杂的物理环境成为可能。
这听起来是不是有点像前几年火过的“元宇宙”?确实有点那味儿了。
生成世界不等于理解世界
我们构建世界模型的最终目的是为了控制和决策,但在采取行动之前,机器必须先理解世界。
现在业界有一条很热闹的捷径,就是通过“生成世界”来试图理解世界。比如 OpenAI 的 Sora、Google 的 Genie、字节的 Seedance,还有李飞飞带来的 World Labs(主攻 3D 生成)。
这类技术的商业化极其丝滑,因为效果“肉眼可见”。但致命伤也很明显:视频生成模型本质上和 LLM 没有区别,只是输入输出的模态变成了像素。 它对于加速度、重力、光线这些物理量的理解是隐式的。LLM 预测下一个 Token,它预测下一帧图片,它无法直接用于物理决策。
人脑看视频,会自动把画面提炼为独立要素(人物、场景、事件)。但视频生成模型眼里,只是一坨像素的概率分布。而且,人类活在 3D 空间,依赖双眼测距;而视频生成依然是个二维游戏,真正要落地还得依赖深度相机或雷达。
真正想搞懂因果关系,目前有两条非常有代表性的路线:
- SIMA 是由 Google DeepMind 提出的通用 AI 智能体。它的核心目标是让一个智能体能在多种不同的 3D 虚拟世界中,通过观察屏幕像素并模拟键盘鼠标操作,直接遵循自然语言指令完成各种任务。SIMA 不依赖特定游戏的 API,而是学习通用的交互技能。最新版本 SIMA 2 整合了 Gemini 大模型,具备了更强的推理、多模态交互和自我改进能力,能够在未知游戏中泛化,甚至接近人类玩家的表现。
- JEPA 是由 Meta 前首席 AI 科学家、图灵奖获得者 Yann LeCun 提出的一种非生成式的世界模型架构,他最近新创办的公司 AMI,就是完全押注在世界模型和物理世界的交互上,而不是走纯文本的 LLM 老路。JEPA 的核心思路不是在像素级别预测未来,而是在一个抽象的表示空间中进行预测。JEPA 通过联合嵌入架构,将输入和预测结果映射到同一个特征空间(有点像 VAE),只保留“可预测”的高层信息,从而忽略难以建模的细节。这种方法旨在让 AI 学会更抽象、更因果性的世界理解,避免生成模型容易出现的累积误差和无效细节。目前已有 I‑JEPA(图像)、V‑JEPA(视频)等变体。
写一个极简的世界模型
为了让这事儿不那么抽象(非程序员的你可以停止阅读了,不然看完就更抽象了。。。),我用 torch 手撸了一个极简的世界模型。
%%{init: {'theme': 'base'}}%%
flowchart TD
%% 定义样式
classDef process fill:#e1f5fe,stroke:#01579b,stroke-width:2px;
classDef model fill:#fff3e0,stroke:#e65100,stroke-width:2px;
classDef decision fill:#e8f5e9,stroke:#1b5e20,stroke-width:2px;
%% 流程逻辑
subgraph Data_Input [输入层]
Obs_t[当前观测 Observation_t]
Act_t[当前动作 Action_t]
end
subgraph WorldModel [WorldModelV3 核心]
Enc[Encoder: 压缩观测]:::model
Dyn[Dynamics: 预测下一隐状态]:::model
Dec[Decoder: 重建观测]:::model
end
subgraph Training_Loop
Decision{Scheduled Sampling<br>判断策略}:::decision
Real_Z[真实隐状态 z_real]
Pred_Z[预测隐状态 z_pred]
end
%% 连接关系
Obs_t --> Enc
Enc -->|生成| Z_t[隐状态 z_t]
Z_t --> Dyn
Act_t --> Dyn
Dyn -->|计算| Pred_Z
Pred_Z --> Dec
Dec -->|输出| Output[重建观测 Predicted_Obs]
%% 循环逻辑
Dyn --> Decision
Real_Z --> Decision
Decision -->|"使用预测 (Pred)"| Z_next[下一时间步 z_t+1]
Decision -->|"使用真实 (Real)"| Z_next
Z_next --> Dyn
%% 应用样式
class Enc,Dyn,Dec process
class Decision decision
假设我们的环境数据长这样:有初始状态、有动作、有由它们共同决定的下一个状态,随着时间步的变化:
--- Time step 1 ---
action: 0.34 | delta: 1 | current position: 8
X (current obs): 0.00 0.03 0.03 0.08 0.03 0.07 0.09 1.00 0.01 0.08 0.03 0.01 0.10 0.04 0.05 0.10
Y (next obs) : 0.10 0.08 0.07 0.10 0.05 0.05 0.06 0.08 1.00 0.08 0.05 0.05 0.06 0.02 0.09 0.07
--- Time step 2 ---
action: -0.45 | delta: -1 | current position: 9
X (current obs): 0.05 0.10 0.05 0.06 0.04 0.00 0.09 0.02 1.00 0.02 0.09 0.01 0.09 0.09 0.07 0.06
Y (next obs) : 0.07 0.09 0.08 0.08 0.04 0.02 0.02 1.00 0.07 0.06 0.01 0.09 0.09 0.02 0.06 0.01
--- Time step 3 ---
action: 1.67 | delta: 1 | current position: 8
X (current obs): 0.05 0.08 0.10 0.03 0.06 0.04 0.03 1.00 0.07 0.03 0.04 0.03 0.01 0.09 0.07 0.06
Y (next obs) : 0.09 0.01 0.00 0.10 0.02 0.09 0.02 0.01 1.00 0.03 0.04 0.01 0.08 0.04 0.00 0.07 这里的核心痛点是多步误差累积——当模型在脑内连续推演(做梦)几十步时,微小的误差会被无限放大。所以代码里我特别加入了 Scheduled Sampling 的训练逻辑,让它在训练后期摆脱对真实数据的依赖,学会自我纠偏。
你可以直接跑一下这段代码,看看模型是如何学会在潜在空间里“做梦”的:
library(torch)
torch_manual_seed(42)
set.seed(42)
# =====================================
# 世界模型演示(WorldModelV3 改进版)
#
# 架构:MLP-based Encoder → Dynamics → Decoder
# - 选用 MLP(而非 RNN/Transformer)的原因:
# 任务为无记忆的马尔可夫过程(当前位置 + 动作 → 下一位置),
# 无需对历史序列建模,MLP 足够且更简洁易解释。
#
# -------------------- 数据生成 --------------------
generate_latent_data <- function(n_samples = 1500, seq_len = 10) {
cat("Generating latent data...\n")
X_data <- array(0, dim = c(n_samples, seq_len, 16 + 1))
Y_data <- array(0, dim = c(n_samples, seq_len, 16))
for (i in 1:n_samples) {
pos <- sample(1:16, 1)
for (t in 1:seq_len) {
obs <- round(runif(16, min = 0, max = 0.1), 2)
obs[pos] <- 1.00
action <- runif(1, -2, 2)
X_data[i, t, ] <- c(obs, action)
# sign(-2~0) = -1 / sign(0) = 0 / sign(0~2) = +1
# 即:负动作向左,零原地,正动作向右
delta <- as.integer(sign(action))
pos <- (pos + delta - 1) %% 16 + 1
next_obs <- round(runif(16, min = 0, max = 0.1), 2)
next_obs[pos] <- 1.00
Y_data[i, t, ] <- next_obs
}
}
list(
X = torch_tensor(X_data, dtype = torch_float()),
Y = torch_tensor(Y_data, dtype = torch_float())
)
}
# -------------------- 模型定义(支持 Scheduled Sampling)--------------------
WorldModelV3 <- nn_module(
"WorldModelV3",
initialize = function(obs_dim = 16, action_dim = 1, latent_dim = 16, d_model = 128) {
# Encoder:观测 → 隐状态(tanh 压缩到 [-1,1])
self$encoder <- nn_sequential(nn_linear(obs_dim, 64), nn_gelu(),
nn_linear(64, latent_dim), nn_tanh())
# Dynamics:(隐状态, 动作) → 下一隐状态(世界模型核心)
self$dynamics <- nn_sequential(
nn_linear(latent_dim + action_dim, d_model),
nn_gelu(), nn_linear(d_model, d_model),
nn_gelu(), nn_linear(d_model, latent_dim), nn_tanh()
)
# Decoder:隐状态 → 重建观测
self$decoder <- nn_sequential(nn_linear(latent_dim, 64), nn_gelu(), nn_linear(64, obs_dim))
},
forward = function(x, scheduled_sampling_rate = 0.5) {
batch_size <- x$size(1)
seq_len <- x$size(2)
actions <- x[, , 17, drop = FALSE]
all_obs <- x[, , 1:16]
# 对所有时间步的观测一次性编码
z_real <- self$encoder(all_obs)
# 预先生成 (seq_len - 1) 步的 use_real mask(可复现)
use_real_mask <- as.logical(torch_bernoulli(torch_full(
c(seq_len - 1L), scheduled_sampling_rate
))$cpu())
predicted_obs_list <- list()
z_current <- z_real[, 1, ] # 第一步必须用真实初始观测
for (t in 1:seq_len) {
action_t <- actions[, t, ]$view(c(batch_size, 1))
dynamics_input <- torch_cat(list(z_current, action_t), dim = 2)
z_next_pred <- self$dynamics(dynamics_input)
obs_next_pred <- self$decoder(z_next_pred)
predicted_obs_list[[t]] <- obs_next_pred
if (t < seq_len) {
z_current <- if (use_real_mask[t]) z_real[, t + 1, ] else z_next_pred
}
}
return(torch_stack(predicted_obs_list, dim = 2))
},
# 纯自回归梦境推演(推理阶段)
dream = function(initial_obs, action_sequence) {
batch_size <- initial_obs$size(1)
seq_len <- action_sequence$size(2)
predicted_obs_list <- list()
z_current <- self$encoder(initial_obs)
for (t in 1:seq_len) {
action_t <- action_sequence[, t, ]$view(c(batch_size, 1))
z_next <- self$dynamics(torch_cat(list(z_current, action_t), dim = 2))
obs_next <- self$decoder(z_next)
predicted_obs_list[[t]] <- obs_next
z_current <- z_next
}
return(torch_stack(predicted_obs_list, dim = 2))
}
)
# -------------------- Scheduled Sampling 训练(指数衰减调度)--------------------
data <- generate_latent_data()
dataset <- tensor_dataset(data$X, data$Y)
dataloader <- dataloader(dataset, batch_size = 64, shuffle = TRUE)
model <- WorldModelV3()
optimizer <- optim_adamw(model$parameters, lr = 1e-3)
loss_fn <- nn_mse_loss()
epochs <- 50
start_rate <- 0.9 # 初始高:多依赖真实数据,梯度稳定
end_rate <- 0.1 # 最终低:多依赖自身预测,抗累积误差
k <- -log(end_rate / start_rate) / epochs
cat("开始 Scheduled Sampling 训练(伯努利随机采样,指数衰减率)\n")
for (epoch in 1:epochs) {
sampling_rate <- start_rate * exp(-k * (epoch - 1))
model$train()
total_loss <- 0
num_batches <- 0
coro::loop(for (b in dataloader) {
x <- b[[1]]
y <- b[[2]]
optimizer$zero_grad()
pred <- model(x, scheduled_sampling_rate = sampling_rate)
loss <- loss_fn(pred, y)
loss$backward()
optimizer$step()
total_loss <- total_loss + loss$item()
num_batches <- num_batches + 1
})
avg_loss <- total_loss / num_batches
if (epoch %% 10 == 0 || epoch == 1) {
cat(sprintf("Epoch %3d | Sampling Rate = %.3f | Loss = %.6f\n", epoch, sampling_rate, avg_loss))
}
}
# =====================================
# 评估一:单样本梦境推演(定性展示)
# =====================================
model$eval()
device <- "cpu"
cat("\n============= 单样本梦境推演 =============\n")
test_idx <- 4
dream_steps <- 7
initial_obs <- data$X[test_idx, 1, 1:16]$view(c(1, 16))$to(device = device)
action_seq <- data$X[test_idx, 1:dream_steps, 17]$view(c(1, dream_steps, 1))$to(device = device)
real_future_obs <- data$Y[test_idx, 1:dream_steps, ]
dreamed_future_obs <- model$dream(initial_obs, action_seq)
initial_pos <- torch_argmax(initial_obs[1, ])$cpu()$item()
cat(sprintf("[起点] 真实位置: %d\n", initial_pos))
success <- 0
for (t in 1:dream_steps) {
act <- action_seq[1, t, 1]$item()
real_pos <- torch_argmax(real_future_obs[t, ])$item()
dream_pos <- torch_argmax(dreamed_future_obs[1, t, ])$cpu()$item()
match <- real_pos == dream_pos
if (match) success <- success + 1
cat(sprintf("Step %d | action %+5.2f | real %2d | dream %2d | %s\n", t, act, real_pos, dream_pos, ifelse(match, "✓", "✗")))
}
cat(sprintf("单样本准确率: %d/%d (%.2f%%)\n\n", success, dream_steps, 100 * success / dream_steps))
# =====================================
# 评估二:多样本平均准确率(定量评估)
# =====================================
cat("============= 多样本平均准确率 =============\n")
n_eval <- 100 # 评估样本数
dream_steps <- 7
correct_per_step <- integer(dream_steps) # 每步累计正确数
for (idx in 1:n_eval) {
init_obs <- data$X[idx, 1, 1:16]$view(c(1, 16))
act_seq <- data$X[idx, 1:dream_steps, 17]$view(c(1, dream_steps, 1))
real_obs <- data$Y[idx, 1:dream_steps, ]
dreamed <- model$dream(init_obs, act_seq)
for (t in 1:dream_steps) {
rp <- torch_argmax(real_obs[t, ])$item()
dp <- torch_argmax(dreamed[1, t, ])$item()
if (rp == dp) correct_per_step[t] <- correct_per_step[t] + 1L
}
}
acc_per_step <- correct_per_step / n_eval * 100
cat(sprintf("%-8s", "Step"))
for (t in 1:dream_steps) cat(sprintf("%6d", t))
cat("\n")
cat(sprintf("%-8s", "Acc(%)"))
for (t in 1:dream_steps) cat(sprintf("%6.1f", acc_per_step[t]))
cat("\n")
cat(sprintf("\n全程平均准确率: %.2f%%\n\n", mean(acc_per_step)))
# =====================================
# 评估三:多步误差累积曲线(可视化核心挑战)
# =====================================
cat("============= 多步误差累积曲线 =============\n")
error_per_step <- 1 - correct_per_step / n_eval
cat("\n误差率随推演步数变化(0=完全正确,1=完全错误):\n\n")
max_bar <- 40
for (t in 1:dream_steps) {
bar_len <- round(error_per_step[t] * max_bar)
bar <- paste(rep("█", bar_len), collapse = "")
cat(sprintf("Step %d [%-40s] %.1f%%\n", t, bar, error_per_step[t] * 100))
}
cat("\n提示:若误差随步数单调递增,说明世界模型存在误差累积——\n")
cat(" 这正是 Scheduled Sampling 训练所要缓解的问题。\n")
跑完代码你会发现,随着推演步数的增加,准确率确实在下降。怎么通用化地去训练这个模型,是走 regression loss 还是走 diffusion loss,这也是目前各大实验室争论和探索的焦点。但无论如何,让 AI 真正“理解”物理世界的齿轮,已经开始转动了。